Neovim AI 插件配置指南
随着 AI 辅助编程的发展,从最开始的 AI Completion 自动补全代码,到 AI chat 通过对话分析代码,再到现在的 AI Agent 自动修改项目,自动化程度越来越高。市面上也出现了非常多的 AI 开发工具,如 cursor 等。但作为一个 vimer,自然忍受不了多个工具互相切换对开发思路的打断。在清明节假期花了几天折腾了一下 neovim 的 AI 开发环境。
随着 AI 辅助编程的发展,从最开始的 AI Completion 自动补全代码,到 AI chat 通过对话分析代码,再到现在的 AI Agent 自动修改项目,自动化程度越来越高。市面上也出现了非常多的 AI 开发工具,如 cursor 等。但作为一个 vimer,自然忍受不了多个工具互相切换对开发思路的打断。在清明节假期花了几天折腾了一下 neovim 的 AI 开发环境。
在内部一个嵌入式平台开发项目中,我们需要将 FFmpeg 交叉编译,用于音视频解码等。我们的使用方式是基于 Conan 打包了对应平台的交叉编译工具链(类似 NDK),并通过 Conan 依赖 ffmpeg/5.1.3。在交叉编译时遇到了以下报错:
1 | ./config.h:18:19: error: expected identifier or '(' before 'void' |
报错日志非常长。除了最开始的 getenv 报错,其他报错都是类似的日志,只是报错的方法不同。统计下来有 cbrt、cbrtf、erf、hypot、lrint、lrintf、rint、round、roundf、trunc、truncf 这些方法。这些方法的特点是都是数学处理相关的函数。
本文详细介绍 Windows 系统中调试符号的概念、分类、生成和使用方法。
在涉及到音视频的代码中,我们通常会使用FourCC格式描述一个音视频格式,包括容器格式,编码格式,像素格式等,其可能的定义和部分相关方法如下
1 | enum FourCC : uint32_t; |
也就是说,FourCC事实上是一个uint32_t的类型,这就导致在调试时,调试器中显示的变量值是一个整型数字,很难直观看到具体内容,除非将其以十六进制显示后,再依次转换成四个字母或数字。以上文中图片为例,若类型为FourCC的变量codec的值为875967048,转换成16进制为0x34363248,再每两个字符转换成一个字母或数字,可得到462H,即H264的逆序(受大小端影响导致)。

Windows下有多种用于采集画面的接口,如GDI,DXGI,以及最新的WGC,但这几种接口都缺乏内容过滤的能力,而具备该能力的采集接口目前仅有古老的放大镜接口(Magnification)。放大镜接口性能极差,BUG众多,目前属于基本废弃的状态。但由于内部业务需求的存在,改采集方式仍然是目前主要使用的采集方式之一。
在放大镜接口众多的bug中,存在一个对稳定性影响非常严重的bug,那就是内存泄漏。放大镜接口提供了一对初始化/反初始化接口MagInitialize和MagUninitialize,但在实际使用中发现,即使在确保二者正确调用的情况下,每次投屏都会出现内存泄漏,泄露量和分辨率相关,但由于官方文档没有任何资料提及这部分内存要如何释放,网上的资料也没有任何相关说明。在和其他同行的交流中得知,一个可行的规避方案是通过将放大镜接口封装成单例类使用,避免多次调用初始化接口。
但这样做的问题是会导致一旦初始化后,放大镜采集接口就会一直占用数百兆内存得不到释放,该问题对32位应用影响较大。由于Windows下32位应用在不开启3G虚拟内存内存的情况下,可用虚拟内存仅2G,除去可执行文件映射占用,实际情况下普遍可用仅1G作用。而对应音视频软件而言,其本身对内存占用是偏高的,这就导致软件在运行时经常出现虚拟内存不出而内存分配失败,进而出现崩溃。根据内部业务崩溃上报数据来看,超过30%的崩溃是由于虚拟内存不足导致的。所以该方案依然不是最佳选择。
libyuv是一个google开发的用于进行原始图像数据转换的C++库,其提供了对多种格式(YUV/RGB)图像的多种转换操作(旋转/缩放/镜像/裁剪/格式转换),目前在内部业务中存在一个图像处理器模块,用于基于libyuv进行原始图像数据的处理,如旋转/缩放/格式转换。每新增一种输入输出的支持,需要编写对应的转换函数,很多转换都需要多次调用libyuv接口,其中大部分都是类似的逻辑,差异点主要在于调用的libyuv接口和参数有差异。以NV12转换成BGRA为例,有如下的转换流程图:
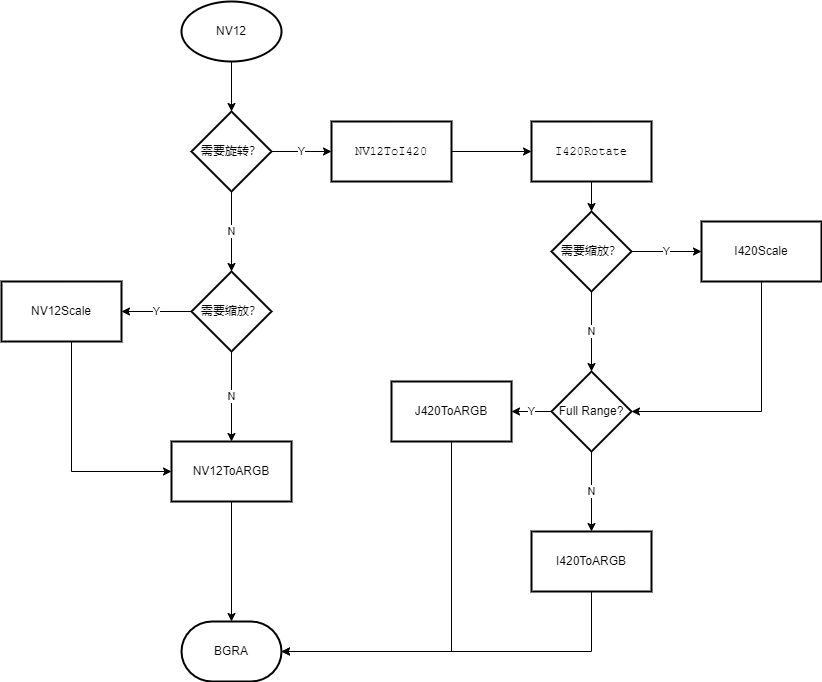
可以看到,每新增一种转换格式支持,一方面需要编写大量代码,另一方面需要自行寻找可用的转换路径,libyuv并没有提供任意格式的转换函数,例如NV12Rotate函数是没有提供现成的,因此只能先转换成I420再旋转或基于更底层API实现一个NV12Rotate。在需要支持的输入输出参数种类较少时,手动编写转换步骤代码还可以接受。但随着业务的需要,需要支持的输入输出格式越来越多,目前仅像素格式(pixel format)需要支持的就多达数十种,再考虑到旋转,缩放等,代码迅速膨胀,维护成本也随之迅速上升。
周末在修改某一款电子游戏的PVF(游戏内容文件)时,遇到了一个问题,我需要将游戏中的原有的穿戴多件装备才有的套装效果修改为一件装备即可激活套装效果。装备套装描述文件如下图所示。

可以看到文件类似于XML格式,每个piece set ability描述了穿戴n件套时对应的效果及描述。我需要将分布在多个piece set ability标签中的子标签的内容合并到一个piece set ability标签中。这样就可以实现一件装备即可激活套装效果的功能。
由于游戏中的套装较多,对应文件有170个,单个文件手动修改要40-50秒,所有文件改完需要大约2个小时。这个工作量对于我来说太大了。这里的工作基本上是重复性的,完全可以通过正则表达式来实现自动替换。