踩坑记 - 消失的代码
踩坑
最近在开发一个跨平台的 C++库时,在 Linux 平台运行非常正常,但在 Windows 下却怎么都没有预期的输出。为了简化问题,这里有一个存在同样问题的示例,可以看到示例中的代码非常简单,很显然预期输出应该是 5。
1 |
|
然而这个示例项目使用 VS 打开并编译运行后,输出结果却是 0。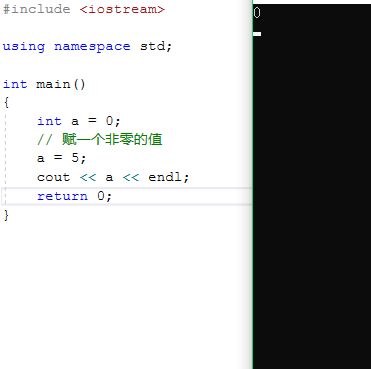
出坑
相信绝大部分人第一反应和我一样,这怎么可能???于是单步调试,更奇怪的事出现了,执行完a = 5;后,a 的值居然没有任何变化,难道这行代码被优化掉了?但这里完全没有优化的可能,编译器不可能犯这么低级的错误。目前可以确定问题就出在对 a 的赋值。然而单从代码上完全看不出任何异常,因此只能尝试去看生成的汇编代码。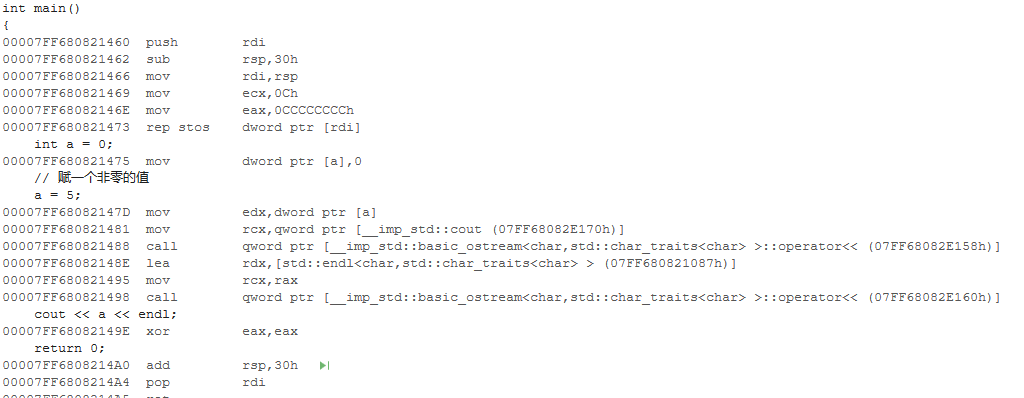
仔细观察生成的汇编代码,可以看到a = 5;这行代码和对应的汇编完全风马牛不相及,对应的汇编应该是cout << a << endl;这行代码的。理论上a = 5;对应的汇编代码应该是mov dword ptr [a], 5,可是整个程序的汇编中也没看到这一句。难道这行代码莫名其妙的消失了?我又尝试关闭编译器优化,修改赋值方式等各种方式,但均以失败告终。问题分析陷入了困境。
在寻求一名同事帮助后,该同事让我生成一个 exe 提供给他用反编译程序分析,为了便于定位,同事让我在消失的代码前添加一句printf("");,添加时我偶然将代码中的注释移除了。该同事拿到生成的 exe 后告诉我说反汇编出来的程序是有对 a 进行赋值 5 的语句的。难道是 VS 的反汇编出错了?我又再次使用 VS 查看了反汇编代码,结果消失的代码对应的汇编代码居然出现了,运行程序,正是预期的结果。难道printf有特殊的魔力?我又将printf("");移除,再次编译运行,结果依然符合预期。查看反汇编,也是很正常的。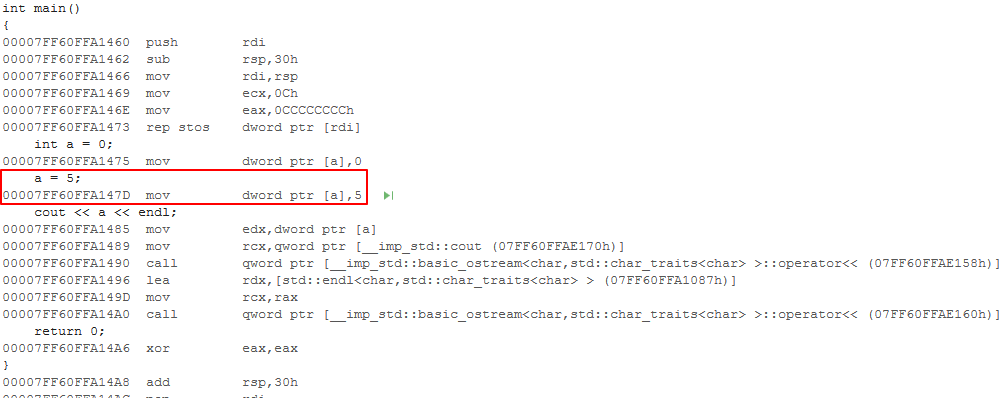
我突然想到,会不会是移除的那行注释有问题?我尝试将注释恢复,再次编译运行,果然,输出又变成了 0。可以确定这行注释有问题了,这行注释导致下一行代码没有被编译。但为什么注释怎么会影响到代码呢?再仔细看一下注释,是一串中文注释。突然就明白了。
这里需要提一下就是这个项目由于是跨平台的,开发是在 Linux 进行的,因此代码文件是UTF-8 without BOM格式,换行符为LF。而默认情况下,MSVC 编译器对于文件编码的处理规则是如果没有 BOM 头,那么就认为这个一个ANSI文件格式,对于中文 Windows 环境,ANSI也就是GBK编码格式。只有在存在UTF-8 with BOM格式的文件才会认为是UTF-8编码的。而类UNIX系统对于UTF-8,默认都是不加BOM头的。这就导致如果是类UNIX下开发的项目如果没有刻意修改过文件编码方式,在 VS 中会将这些实际上是以UTF-8编码的文件以GBK编码去错误地解析,进而可能导致各种问题。比较常见的情况是在编译时会提示警告C4819
warning C4819: 该文件包含不能在当前代码页(936)中表示的字符。请将该文件保存为 Unicode 格式以防止数据丢失
然而有一种比较特殊的情况就是本文中遇到的问题。这里先简单介绍下UTF-8和GBK的编码和解码方式。这两种编码方式都是兼容ASCII编码的,也就是英文字符和部分符号是在这两种编码方式下对应的字节是完全一样的。而对于汉字(最常见的就是在中文注释),在使用UTF-8编码时一个汉字会被编码成 3 个字节,使用GBK编码时则是一个汉字被编码成 2 个字节,解码要复杂一些,这里我们可以简单的认为对于中文字符编码后的字节,UTF-8每读取 3 个字节解析成一个汉字,而GBK每读取 2 个字节解析成一个汉字,如果发现编码没能成功解析出对应的汉字,VS 就会产生上面提到的C4819警告。
因此对于上面这个示例代码中的中文注释,一共七个汉字,UTF-8编码后保持在文件里时应该是 21 个字节。而 VS 误认为这是一个GBK编码文件,在读取注释中文对应的 21 个字节时,每 2 个字符解析成一个汉字,这里凑巧前 20 个字节在以GBK编码解析时都解析出了对应的汉字,因此没有任何警告。这样读取了 20 个字节后,还剩下一个字节,对于编译器来说它并不知道已经到了行尾了, 为了继续解析文件,还需要往后再读取一个字节。这个被误读取的字节就是换行符。刚我们提到这个文件是以LF结尾的,只有一个字符,因此相当于注释所在行的换行符被吞了,和中文对应的 21 个字节中最后一个字节一起被错误的解析成了一个汉字。这样就导致在编译器看来,下一行代码和注释所在行是同一行,也就是说编译器看到的是类似如下的代码,其中 X 表示GBK解析出来的没有意义的汉字。
1 |
|
所以实际上编译器和编辑器看到的代码根本就是不一样的,对于编译器来说,a = 5;是一行不存在的代码。
填坑
理解了上面的原因后,这个问题解决起来就很简单了,至少有以下几种方式可以处理这个问题。
- 移除掉中文注释或使用英文注释代替。简单粗暴,但如果是一个比较大的项目,其他地方可能还有中文注释,不可能全部移除或修改,工作量太大还容易遗漏。
- 将源码文件使用
UTF-8 with BOM格式编码。但这样对于一个跨平台项目来说可能会导致其他平台下出现莫名其妙的问题,网上有很多案例。 - 为
MSVC添加/utf-8的编译选项。在较新(据说是Visual Studio 2015 Update 2之后)的VS版本中,添加了/utf-8编译选项,用于告诉编译器将源码文件视为使用UTF-8编码。
我的这个项目使用的是VS 2017,因此选择了最后一种方式。